LLaMA-3 8B 计算规模、信息流与能耗
整合自对话记录与 LLaMA-3 8B 架构图(Llm arch 1080P.html),涵盖 LLaMA-3 8B 架构参数、现代设计改动的来龙去脉(GQA / RoPE / SwiGLU / KV Cache)、完整前向传播数值演示,以及 FLOPs 与训练能耗的关系。
一、LLaMA-3 8B 基本参数
| 参数 | 数值 |
|---|---|
| 模型名称 | LLaMA-3 8B |
| 发布机构 | Meta |
| 发布日期 | 2024-04-18 |
| 架构类型 | Decoder-only Transformer |
| 参数量 | 约 8.03B |
| 训练 token 数 | 15T+ |
| 上下文长度 | 8,192 tokens |
| 词表大小 $\lvert V\rvert$ | 128,256 |
| 层数 $L$ | 32 |
| 模型维度 $d_{\text{model}}$ | 4,096 |
| Query heads $n_q$ | 32 |
| KV heads $n_{kv}$ | 8 |
| 每头维度 $d_{\text{head}}$ | 128(= 4096 ÷ 32) |
| GQA 分组比例 | 每 4 个 Query head 共享 1 组 KV |
| SwiGLU 中间维度 | 14,336 |
| 位置编码 | RoPE,$\theta = 500{,}000$ |
| Norm 方式 | Pre-RMSNorm |
| 权重精度 | BF16 |
| Embedding / LM Head | 不共享权重 |
二、从 GPT-3 到 LLaMA-3:四个关键设计改变
在看具体计算之前,先弄清楚 LLaMA-3 和 GPT-3 的核心区别在哪里。
| 组件 | GPT-3(旧设计) | LLaMA-3 8B(新设计) | 改变的动机 |
|---|---|---|---|
| 归一化 | Pre-LayerNorm | Pre-RMSNorm | RMSNorm 省去均值计算,速度更快,效果持平 |
| 注意力头 | MHA(96Q / 96KV) | GQA(32Q / 8KV) | KV Cache 显存降为 1/4 |
| 位置编码 | 绝对位置 Embedding(加法) | RoPE(旋转乘法) | 天然表达相对位置,长上下文外推更好 |
| FFN 激活 | GELU(两次矩阵乘法) | SwiGLU(三次矩阵乘法,加门控) | FFN 表达力更强 |
这四个改变是 2021~2024 年间大语言模型研究积累的工程经验,每一个都有具体的数值意义,下面逐步展开。
三、完整前向传播:用具体数值走一遍
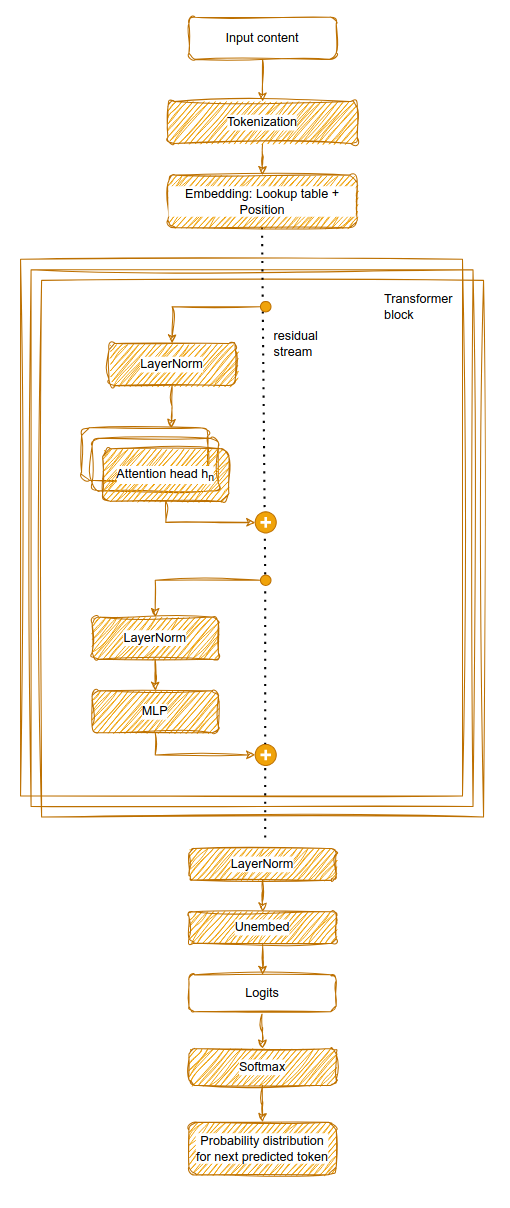
先追踪 1 个 token,感受张量形状;最后乘以批量感受总规模。
第一步:Embedding 查表
词表矩阵的形状:
$$E \text{ 的形状} = [128256,\ 4096] \quad \text{参数量} = 128256 \times 4096 = \textbf{5.25 亿}$$假设句子 "猫追鱼",分词后得到 3 个 token(实际 tokenizer 可能不同,此处为示意):
$$x_1 = \text{猫},\quad x_2 = \text{追},\quad x_3 = \text{鱼}$$取出 "猫" 对应的行:
$$x_\text{猫} \text{ 的形状} = [1,\ 4096]$$重要:LLaMA-3 不在 Embedding 层加位置信息。
GPT-3 会在这一步把位置 Embedding 叠加到词 Embedding 上($x_0 = \text{Emb} + \text{PosEmb}$)。LLaMA-3 没有独立的位置 Embedding 表,位置信息通过后面的 RoPE 旋转进 Q 和 K,不改变这里的 $x_\text{猫}$。
第二步:Pre-RMSNorm
形状不变:$[1,\ 4096] \rightarrow [1,\ 4096]$
LLaMA-3 在每个 Block 的注意力和 FFN 之前各做一次 RMSNorm(Pre-Norm)。GPT-3 同样使用 Pre-Norm 顺序(Pre-LayerNorm),区别在于 LLaMA-3 把 LayerNorm 换成了计算更轻量的 RMSNorm。
Post-Norm 在残差连接之后才归一化:
$$y = \text{Norm}(x + F(x))$$问题是:$x + F(x)$ 这一步直接把两个向量相加,当网络很深时,梯度会在大量层的残差路径上累积,导致训练不稳定(exploding/vanishing gradients)。
Pre-Norm 在进入 $F$ 之前先归一化:
$$y = x + F(\text{Norm}(x))$$残差路径 $x$ 直接连通到输出,梯度可以无阻碍地通过残差跳过所有层,训练深层模型更稳定。代价是归一化的正则化效果略弱一些,但工程上训练稳定性更重要。
LLaMA-3 vs GPT-3 归一化的真正区别:两者都用 Pre-Norm 顺序(先 Norm,再做注意力/FFN),区别不在于 Pre vs Post,而在于 Norm 的类型——GPT-3 用 LayerNorm(含均值计算),LLaMA-3 用 RMSNorm(去掉均值,只保留 RMS 缩放)。
LayerNorm 需要:
- 计算均值 $\mu = \frac{1}{d}\sum_i x_i$
- 计算方差 $\sigma^2 = \frac{1}{d}\sum_i (x_i - \mu)^2$
- 标准化:$\hat{x}_i = (x_i - \mu)/\sqrt{\sigma^2 + \epsilon}$
- 缩放和平移:$y_i = \gamma_i \hat{x}_i + \beta_i$
RMSNorm 省掉了均值计算和平移参数 $\beta$:
$$\text{RMS}(x) = \sqrt{\frac{1}{d}\sum_{i=1}^{d} x_i^2 + \epsilon}$$ $$y_i = \frac{x_i}{\text{RMS}(x)} \cdot w_i$$其中 $d = 4096$,$w$ 是可训练缩放参数,形状 $[4096]$。
实验发现去掉"减均值"这一步后质量下降极少,但计算量明显减少——均值需要两遍扫描(先算均值再算方差),RMS 只需一遍。
第三步:GQA 注意力——四次矩阵乘法
GQA(Grouped Query Attention,分组查询注意力)是 LLaMA-3 相较于 GPT-3 在注意力层最大的结构差异。
生成 Q、K、V:形状不对称
Q 投影(32 个 Query head):
$$Q = x \cdot W_Q \quad [1,\ 4096] \times [4096,\ 4096] \rightarrow [1,\ 4096]$$切分为 32 个 Query head,每头 128 维:
$$[1,\ 4096] \rightarrow 32 \text{ 个头,每头} [1,\ 128]$$K 投影(只有 8 个 KV head):
$$K = x \cdot W_K \quad [1,\ 4096] \times [4096,\ 1024] \rightarrow [1,\ 1024]$$切分为 8 个 KV head,每头 128 维:
$$[1,\ 1024] \rightarrow 8 \text{ 个头,每头} [1,\ 128]$$V 投影(同样 8 个 KV head):
$$V = x \cdot W_V \quad [1,\ 4096] \times [4096,\ 1024] \rightarrow [1,\ 1024]$$ $$[1,\ 1024] \rightarrow 8 \text{ 个头,每头} [1,\ 128]$$形状一览:
| 矩阵 | $W$ 形状 | 参数量 | 输出维度 |
|---|---|---|---|
| $W_Q$ | $[4096,\ 4096]$ | 1677 万 | $[1,\ 4096]$ |
| $W_K$ | $[4096,\ 1024]$ | 419 万 | $[1,\ 1024]$ |
| $W_V$ | $[4096,\ 1024]$ | 419 万 | $[1,\ 1024]$ |
| $W_O$ | $[4096,\ 4096]$ | 1677 万 | $[1,\ 4096]$ |
注意力头数量的三种设计:
| 类型 | Q heads | K/V heads | 代表模型 | KV Cache |
|---|---|---|---|---|
| MHA(多头注意力) | $h$ | $h$ | GPT-3、BERT | 最大 |
| MQA(多查询注意力) | $h$ | 1 | PaLM | 最小,质量有损 |
| GQA(分组查询注意力) | $h$ | $g$($1 < g < h$) | LLaMA-3、Gemma | MHA 的 $g/h$ |
MHA 每个 Q head 有独立的 K 和 V,效果最好,但推理时 KV Cache 最大。
MQA 把所有 Q head 的 K、V 合并成 1 组,KV Cache 最小,但 K/V 表达力下降,模型质量有所损失。
GQA 是中间方案:把 $h$ 个 Q head 分成 $g$ 组,每组共享一对 K/V head。LLaMA-3 8B 的分组是 32Q / 8KV,每 4 个 Q head 共享 1 个 KV head:
Q head 0, 1, 2, 3 → 共用 KV head 0
Q head 4, 5, 6, 7 → 共用 KV head 1
...
Q head 28, 29, 30, 31 → 共用 KV head 7共享的是投影矩阵($W_K, W_V$)产生的 K/V 数据,而不是 Q 向量或 attention 权重——同组 Q head 各自有独立的查询方向,只是从同一份 K/V 里"查资料"。
这不是数学推导的最优解,而是通过消融实验选出的工程经验值。
Ainslie 等人 2023 年的 GQA 论文发现:当每组包含 4 个 Q head 时,模型质量已经非常接近完整 MHA,但 KV Cache 降为 MHA 的 1/4。继续增大分组(比如 8:1、16:1)质量开始明显下降,而减小分组(2:1)收益有限。
LLaMA-3 8B 在 $d_\text{model} = 4096$、$n_q = 32$ 的前提下选了 $n_{kv} = 8$(分组比 4:1),是效果与效率的实用平衡点。
假设输入是 "猫追鱼"(3 个 token)。
- "每 4 个 Q head 共享 1 个 KV head" 里的"4"是头的编号,描述注意力头的分组结构,和序列长度(3 个 token)没有关系。
- 3 个 token 是序列维度:每个 KV head 在每个 token 位置都有一个独立的 K/V 向量。
展开来看,KV head 0 的数据是这样的:
KV head 0:
位置 1(猫):k₁,₀ = [1.0, 0.5, ...] v₁,₀ = [0.3, -0.1, ...] ← 128 个数
位置 2(追):k₂,₀ = [0.6, -0.2, ...] v₂,₀ = [0.1, 0.8, ...]
位置 3(鱼):k₃,₀ = [0.2, 0.4, ...] v₃,₀ = [0.6, 0.2, ...]Q head 0、1、2、3 共享的是上面这整组数据,但各自用自己的 Q 向量与这些 K 做点积,得到各自独立的 attention 权重和输出。
"共享 KV"不等于"共享一个向量"——每个序列位置的 K/V 是不同的,共享的是投影矩阵(也就是生成这些 K/V 所用的 $W_K, W_V$)。
RoPE:把位置旋转进 Q 和 K
RoPE 只作用在 Q 和 K 上,V 不旋转,形状不变:
$$Q:[1,\ 32,\ 128] \rightarrow Q_{\text{rope}}:[1,\ 32,\ 128]$$ $$K:[1,\ 8,\ 128] \rightarrow K_{\text{rope}}:[1,\ 8,\ 128]$$具体做法:把每个 head 的 128 维向量按两两一组拆成 64 个平面:
$$(x_0,\ x_1),\ (x_2,\ x_3),\ \ldots,\ (x_{126},\ x_{127})$$在位置 $p$,第 $i$ 个平面旋转角度 $\theta_{p,i} = p \cdot \theta_{\text{base}}^{-2i/d_\text{head}}$:
$$\begin{bmatrix} x'_{2i} \\ x'_{2i+1} \end{bmatrix} = \begin{bmatrix} \cos\theta_{p,i} & -\sin\theta_{p,i} \\ \sin\theta_{p,i} & \cos\theta_{p,i} \end{bmatrix} \begin{bmatrix} x_{2i} \\ x_{2i+1} \end{bmatrix}$$核心数学事实:两个经过旋转的向量的点积,只与它们旋转角之差有关,与各自的绝对位置无关。
设 query 在位置 $p$,key 在位置 $s$,旋转矩阵分别是 $R_p$ 和 $R_s$:
$$(R_p q)^\top (R_s k) = q^\top R_p^\top R_s k = q^\top R_{s-p} k$$最终只剩 $R_{s-p}$,即 $s-p$(相对距离)。注意力得分自动包含位置差信息,不依赖 $p$ 或 $s$ 本身。
直观理解:把两个 token 的位置想象成时钟表盘上的两根指针。无论把整个表盘顺时针转多少度,两根指针的夹角不变。RoPE 让 Q 和 K 的点积只感知两者的"夹角差"(相对位置),感知不到各自的"绝对角度"(绝对位置)。
传统绝对位置 Embedding(如 GPT-3)把位置向量加到 token 向量上,位置信息是"叠加"进去的;RoPE 是"旋转"进去的,两者的本质区别在这里。
$\theta_\text{base}$ 控制旋转频率。对第 $i$ 个维度对,旋转速率是 $\theta_\text{base}^{-2i/d}$:
- $\theta_\text{base}$ 越大,旋转越慢
- $\theta_\text{base}$ 越小,旋转越快
原始 RoPE 论文(Su et al., 2021)针对 512 上下文用的是 $\theta_\text{base} = 10{,}000$。LLaMA-3 的上下文是 8,192——是 512 的 16 倍。
如果继续用 10,000,高频维度到第 8192 个位置时已经绕了很多整圈,不同位置会产生相同或接近的旋转角,失去区分度(位置混叠)。
把 $\theta_\text{base}$ 从 10,000 提升到 500,000,相当于把旋转放慢 50 倍,让每个维度在 8192 步内不会绕完整圈,保持位置的唯一性。
计算注意力得分(以"鱼"看全句为例)
以 "鱼"(位置 3)为例,Q head 0 使用 KV head 0 的数据。
Step 1:Q、K 的值(已应用 RoPE,旋转角不同的两个 token 点积自然包含相对距离)
$$q_3 = x_\text{鱼} \cdot W_{Q,\text{head0}} \quad [1,\ 128]$$ $$k_1 = x_\text{猫} \cdot W_{K,\text{KV0}} = [0.4,\ 0.7,\ 0.1,\ \ldots] \quad \text{("猫",128个数)}$$ $$k_2 = x_\text{追} \cdot W_{K,\text{KV0}} = [0.6,\ 0.3,\ -0.2,\ \ldots] \quad \text{("追",128个数)}$$ $$k_3 = x_\text{鱼} \cdot W_{K,\text{KV0}} = [0.2,\ 0.5,\ 0.4,\ \ldots] \quad \text{("鱼"自己,128个数)}$$Step 2:计算得分(除以 $\sqrt{128} \approx 11.3$)
$$\text{score}(x_3, x_1) = \frac{q_3 \cdot k_1^\top}{11.3} \approx 0.029$$ $$\text{score}(x_3, x_2) = \frac{q_3 \cdot k_2^\top}{11.3} \approx 0.046$$ $$\text{score}(x_3, x_3) = \frac{q_3 \cdot k_3^\top}{11.3} \approx 0.063$$Step 3:Softmax 归一化(因果掩码:"鱼"在位置 3,可以看 1、2、3,看不到未来)
$$[\alpha_{31},\ \alpha_{32},\ \alpha_{33}] = \text{softmax}([0.029,\ 0.046,\ 0.063]) \approx [0.328,\ 0.333,\ 0.339]$$验算:$e^{0.029} \approx 1.0294,\ e^{0.046} \approx 1.0471,\ e^{0.063} \approx 1.0650$,和 $\approx 3.1415$;各除以和得 $[0.328,\ 0.333,\ 0.339]$,三者之和 $= 1.000$。✓
| token | 注意力权重 | 解读 |
|---|---|---|
| "猫" | 32.8% | "鱼"对"猫"的关注程度 |
| "追" | 33.3% | "鱼"对"追"的关注程度 |
| "鱼"自己 | 33.9% | "鱼"对自身的关注程度 |
三者分数差距很小(0.029 / 0.046 / 0.063),Softmax 之后权重也相近,"鱼"对全句各位置关注较为均匀。
Step 4:加权求和,单头输出(公式等同于 GPT-3 的单头 attention)
$$\text{head}_3 = 0.328 \times v_1 + 0.333 \times v_2 + 0.339 \times v_3$$输出形状:$[1,\ 128]$
Step 5:32 个 head 拼接
$$32 \times 128 = 4096 \rightarrow \text{concat} = [1,\ 4096]$$O 投影(第 4 次矩阵乘法):
$$[1,\ 4096] \cdot W_O[4096,\ 4096] \rightarrow [1,\ 4096]$$$W_O$ 的作用:32 个 head 的输出只是简单拼接,$W_O$ 重新混合来自不同 head 的信息,让各 head 的语义真正融合。
以下展开对 GQA 多头注意力完整计算流程的说明。
多头注意力完整流程图(LLaMA-3 8B GQA 版)
x₃("鱼")[1, 4096]
│
┌───┴──────────── 32 个 Q head 并行 ────────────────────┐
│ │
│ Q head 0,1,2,3 → 共用 KV head 0 │
│ Q head 4,5,6,7 → 共用 KV head 1 │
│ ... │
│ Q head 28,29,30,31 → 共用 KV head 7 │
│ │
│ (以 Q head 0 为例) │
├── q₃ = x₃ × W_Q[4096,128] → [1,128]
├── k₁,k₂,k₃ = x₁,x₂,x₃ × W_K[4096,128] → 各 [1,128] ← KV head 0
├── v₁,v₂,v₃ = x₁,x₂,x₃ × W_V[4096,128] → 各 [1,128]
├── score = q₃·kⱼᵀ / √128
├── softmax → α₃₁,α₃₂,α₃₃
└── Σαⱼ·vⱼ → head₀ [1,128]
│ │
└──────────── 拼接 concat ──────────────────────────────┘
[1, 4096](= 32 × 128)
│
× W_O [4096,4096]
│
[1, 4096]量纲自检:注意力层
| 检查项 | 计算 | 结果 |
|---|---|---|
| $W_Q$ 参数量 | $4096 \times 4096$ | 16,777,216 ✓ |
| $W_K$ 参数量 | $4096 \times 1024$ | 4,194,304 ✓ |
| $W_V$ 参数量 | $4096 \times 1024$ | 4,194,304 ✓ |
| $W_O$ 参数量 | $4096 \times 4096$ | 16,777,216 ✓ |
| Q 切分后每头维度 | $4096 \div 32$ | $128 = d_\text{head}$ ✓ |
| K/V 切分后每头维度 | $1024 \div 8$ | $128 = d_\text{head}$ ✓ |
| 拼接维度 | $32 \times 128$ | $4096 = d_\text{model}$ ✓ |
| $W_O$ 输入维度 | 拼接后 $[1,\ 4096]$ | 与 $W_O$ 行数匹配 ✓ |
| GQA 每组 Q 数 | $32 \div 8$ | 每 4 个 Q 共享 1 个 KV ✓ |
第四步:残差连接
$$x_1 = x_0 + \text{attn\_out} \quad [1,\ 4096]$$第五步:SwiGLU 前馈网络——三次矩阵乘法
GPT-3 的 FFN 是两次矩阵乘法;LLaMA-3 的 SwiGLU FFN 需要三次。
先做第二个 Pre-RMSNorm(形状不变),然后走两条并行的上投影路径:
Gate 投影:
$$[1,\ 4096] \cdot W_{\text{gate}}[4096,\ 14336] \rightarrow [1,\ 14336]$$再过 SiLU 激活函数:
$$\text{SiLU}(G) = G \cdot \sigma(G) \quad \text{形状不变} [1,\ 14336]$$SiLU 输出接近 0 的地方"关门",输出大正数的地方"全开",是一个连续可微的"开关"。
Up 投影:
$$[1,\ 4096] \cdot W_{\text{up}}[4096,\ 14336] \rightarrow [1,\ 14336]$$逐元素相乘(门控):
$$M = \text{SiLU}(G) \odot U \quad [1,\ 14336]$$Down 投影(降维):
$$[1,\ 14336] \cdot W_{\text{down}}[14336,\ 4096] \rightarrow [1,\ 4096]$$GPT-3 的 GELU FFN:
$$x \xrightarrow{W_1\ [4096 \to 16384]} [1,\ 16384] \xrightarrow{\text{GELU}} [1,\ 16384] \xrightarrow{W_2} [1,\ 4096]$$只有一条路:升维 → 激活 → 降维。激活函数作用在所有 16384 个特征上($4 \times d_\text{model} = 4 \times 4096$),每个特征被"拧一下",但没有对不同特征的选择性控制。
SwiGLU 的 FFN:
$$x \to \underbrace{\text{SiLU}(xW_\text{gate})}_{\text{门控信号,控制"开多少"}} \odot \underbrace{xW_\text{up}}_{\text{特征内容}} \xrightarrow{W_\text{down}} \text{输出}$$$W_\text{gate}$ 产生一个和特征维度对应的"阀门",控制每个中间特征通道的通量;$W_\text{up}$ 提供实际的特征内容;两者逐元素相乘后,被门控值压低的特征对输出贡献变小。
类比:普通 GELU FFN 像是一排水管全部打开后统一拧一下(激活);SwiGLU 是对每根水管装了独立的阀门($W_\text{gate}$),模型可以动态决定哪些中间特征通,哪些堵。
普通 GELU FFN 升维 4 倍:$4096 \times 4 = 16384$。
SwiGLU 有两个上投影矩阵($W_\text{gate}$ 和 $W_\text{up}$),如果同样升到 16384,参数量是:
$$2 \times 4096 \times 16384 + 16384 \times 4096 = 3 \times 4096 \times 16384 \approx 2.01 \text{ 亿}$$而普通 FFN(2 次乘法)的参数量是:
$$2 \times 4096 \times 16384 = 1.34 \text{ 亿}$$如果想让 SwiGLU 的参数量与普通 2 矩阵 GELU FFN(升 4 倍:$d \to 4d$)严格相当,令:
$$3 \times d \times h_{\text{parity}} = 2 \times d \times 4d \implies h_{\text{parity}} = \frac{8d}{3} = \frac{8 \times 4096}{3} \approx 10923$$取 128 对齐(GPU warp 效率):$85 \times 128 = 10880$ 或 $86 \times 128 = 11008$。
但 LLaMA-3 实际选了 14336($= 112 \times 128 = 3.5d$),比参数齐平点大约 30%。 这是一个工程经验值:Meta 在消融实验中发现 14336 在模型质量与参数量之间取得了更好的平衡,比严格参数齐平的 11008 效果更好;同时 $14336 = 2^{11} \times 7$ 对 GPU 内存对齐友好。
验算:$3 \times 4096 \times 14336 \approx 1.76$ 亿,比严格齐平方案($\approx 1.34$ 亿)多约 30%,但 SwiGLU 换来了更强的门控表达力,工程上认为值得。
量纲自检:FFN 层
| 检查项 | 计算 | 结果 |
|---|---|---|
| Gate 投影输出 | $[1,\ 4096] \times [4096,\ 14336]$ | $[1,\ 14336]$ ✓ |
| Up 投影输出 | $[1,\ 4096] \times [4096,\ 14336]$ | $[1,\ 14336]$ ✓ |
| SiLU 激活 | $[1,\ 14336]$ 逐元素 | $[1,\ 14336]$ ✓ |
| 门控相乘 | $[1,\ 14336] \odot [1,\ 14336]$ | $[1,\ 14336]$ ✓ |
| Down 投影输出 | $[1,\ 14336] \times [14336,\ 4096]$ | $[1,\ 4096]$ ✓ |
| 第二残差 | $[1,\ 4096] + [1,\ 4096]$ | $[1,\ 4096]$ ✓ |
第六步:Unembedding + Softmax
经过 32 层后,做 Final RMSNorm,再经过 LM Head:
$$h_\text{final} [1,\ 4096] \cdot U[4096,\ 128256] \rightarrow [1,\ 128256]$$Softmax 后得到 128,256 个词的概率分布,取样得到下一个 token。
完整数据流
1 个 token(id = 某整数)
↓ Embedding [128256, 4096]
x₀: [1, 4096]
↓ × 32 层,每层:
│
├─ Pre-RMSNorm → [1, 4096]
├─ × W_Q [4096,4096] → Q: [1,4096] → 32 头,每头 [1,128]
├─ × W_K [4096,1024] → K: [1,1024] → 8 头,每头 [1,128]
├─ × W_V [4096,1024] → V: [1,1024] → 8 头,每头 [1,128]
├─ RoPE(Q, K) → 形状不变,点积编入相对位置信息
├─ GQA:每 4 个 Q head 共用 1 个 KV head
├─ 注意力得分 + 加权求和 → 32 头输出各 [1,128] → 拼接 [1,4096]
├─ × W_O [4096,4096] → [1,4096]
├─ ⊕ 残差连接 → [1,4096]
├─ Pre-RMSNorm → [1, 4096]
├─ × W_gate [4096,14336] → SiLU → [1,14336] ─┐ 两路并行
├─ × W_up [4096,14336] → [1,14336] ─┘
├─ ⊙ 逐元素相乘(门控)→ [1,14336]
├─ × W_down [14336,4096] → [1,4096]
└─ ⊕ 残差连接 → [1,4096]
↓ 32 层后
h_final: [1, 4096]
↓ Final RMSNorm → [1, 4096]
↓ × LM Head [4096, 128256]
logits: [1, 128256]
↓ Softmax / top-p / top-k
预测的下一个 token四、一层 Block 参数量汇总
| 组件 | 矩阵形状 | 参数量 |
|---|---|---|
| $W_Q$ | $[4096,\ 4096]$ | 16,777,216 |
| $W_K$ | $[4096,\ 1024]$ | 4,194,304 |
| $W_V$ | $[4096,\ 1024]$ | 4,194,304 |
| $W_O$ | $[4096,\ 4096]$ | 16,777,216 |
| Attention 合计 | 41,943,040 | |
| $W_\text{gate}$ | $[4096,\ 14336]$ | 58,720,256 |
| $W_\text{up}$ | $[4096,\ 14336]$ | 58,720,256 |
| $W_\text{down}$ | $[14336,\ 4096]$ | 58,720,256 |
| SwiGLU 合计 | 176,160,768 | |
| 两个 RMSNorm | $[4096] \times 2$ | 8,192 |
| 一层合计 | 218,112,000 |
与 GPT-3 的横向对比:
| GPT-3 一层 | LLaMA-3 8B 一层 | |
|---|---|---|
| Attention 参数 | $4 \times 12288^2 = $ 6.04 亿(MHA) | 4194 万(GQA 减少 37.5%) |
| FFN 参数 | $2 \times 12288 \times 49152 = $ 12.08 亿 | 1.76 亿(参数量 $\approx$ 1/7) |
| 一层合计 | 18.1 亿 | 2.18 亿 |
两者整体规模比:$175\text{B} / 8\text{B} \approx 21.8$ 倍;但一层参数比约 $1812\text{M} / 218\text{M} \approx 8.3$ 倍,远小于整体比。原因:GPT-3 有 96 层,LLaMA-3 只有 32 层,层数之比约 3×,$8.3 \times 3 \approx 25$,与整体比 21.8× 数量级一致(差异来自 Embedding 等非块参数占比不同)。
五、32 层累计与总参数量
$$32 \times 218{,}112{,}000 = 6{,}979{,}584{,}000$$Embedding:
$$128{,}256 \times 4{,}096 = 525{,}336{,}576$$LM Head(不共享权重):
$$4{,}096 \times 128{,}256 = 525{,}336{,}576$$Final RMSNorm:$4{,}096$
总计:
$$6{,}979{,}584{,}000 + 525{,}336{,}576 + 525{,}336{,}576 + 4{,}096 = \textbf{8{,}030{,}261{,}248}$$约 8.03B 参数。✓ 与标称一致。
很多早期语言模型(如 GPT-2)把 Embedding 矩阵和 LM Head 绑定为同一份参数(Weight Tying),即 $U = E^\top$,可以节省 $\lvert V \rvert \times d = 5.25$ 亿参数。
LLaMA-3 选择不共享。原因:Embedding 的职责是把离散 token id 映射到连续语义空间,LM Head 的职责是把连续表示打分回词表概率——两者的优化方向在充分训练后往往有所分歧。Meta 实验发现在 15T+ token 的规模下,不共享权重能带来轻微质量提升,代价是多占 5.25 亿参数的显存。
六、KV Cache:为什么 GQA 对推理至关重要
自回归推理时,每生成一个新 token,旧 token 的 $K$ 和 $V$ 不需要重新计算——只需在第一次经过时把它们存起来,后续生成直接读取。
一层前向传播有许多中间激活(Q、K、V、注意力得分、FFN 升维结果……),但只有 K 和 V 能被复用:
- K 和 V 只取决于对应位置的 token 输入,不依赖当前新 token
- Q 是当前新 token 自己产生的,每步都不同,不能 cache
- FFN 的中间激活也依赖当前 token,不能 cache
所以 KV Cache 存的是:
$$\text{每层} \times \text{每个历史 token} \times \{K_\text{head}, V_\text{head}\} \times n_{kv} \text{ 组}$$LLaMA-3 8B 的 KV Cache 计算:
一层、一个 token 需要存储的元素数:
$$K \text{ 部分:} n_{kv} \times d_\text{head} = 8 \times 128 = 1024 \text{ 个数}$$ $$V \text{ 部分:} n_{kv} \times d_\text{head} = 8 \times 128 = 1024 \text{ 个数}$$BF16 每个数 2 字节:
$$2048 \times 2 = 4096 \text{ bytes} = 4 \text{ KB / token / 层}$$32 层:
$$32 \times 4 \text{ KB} = \textbf{128 KB / token}$$| 上下文长度 | BF16 KV Cache(batch = 1) |
|---|---|
| 1,024 | 128 MB |
| 8,192 | 1 GB |
| 32,768 | 4 GB |
| 128,000 | 15.6 GB |
如果用 MHA(32 个 KV head 而不是 8 个):
$$2 \times 32 \times 128 \times 2 \times 32 = 524{,}288 \text{ bytes} = 512 \text{ KB / token}$$8K 上下文:
$$8192 \times 512 \text{ KB} = \textbf{4 GB}$$GQA 把 8K 上下文的 KV Cache 从 4 GB 降到 1 GB——降为 1/4。
直觉:KV Cache 大小 = 层数 × KV head 数 × head 维度 × 序列长度 × 精度字节数。GQA 把 KV head 从 32 砍到 8,其余不变,Cache 直接缩小 4 倍。
七、FLOPs 计算:Prefill 与 Decode 分开看
推理分两个阶段,计算特征完全不同:
| 阶段 | 含义 | 计算特点 |
|---|---|---|
| Prefill | 一次性读入完整 prompt | 矩阵×矩阵,算力利用高;attention 有 $S^2$ 项 |
| Decode | 每步生成 1 个新 token | 矩阵×向量,受显存带宽瓶颈 |
Prefill(seq_len = 8192,32 层)
一层线性层 FLOPs(attention 4 次 + FFN 3 次,共 $41.9\text{M} + 176.2\text{M} = 218.1\text{M}$ 参数):
$$2 \times 8192 \times 218{,}103{,}808 \approx 3.57 \times 10^{12}$$一层 attention 二次项($QK^\top$ + $AV$):
$$2 \times 2 \times n_q \times S^2 \times d_\text{head} = 2 \times 2 \times 32 \times 8192^2 \times 128 \approx 1.10 \times 10^{12}$$32 层总 FLOPs:
$$32 \times (3.57 + 1.10) \times 10^{12} \approx \textbf{1.50 \times 10^{14}}$$即 8K prompt 的一次 prefill 约 150 TFLOPs。
Decode(已有 8192 token 的 KV Cache,生成第 8193 个 token)
一层线性层(仅 1 个 token):
$$2 \times 1 \times 218{,}103{,}808 \approx 4.36 \times 10^8$$一层 attention(1 个 query token 看 8193 个历史 token):
$$2 \times 2 \times 32 \times 1 \times 8193 \times 128 \approx 1.34 \times 10^8$$32 层合计:
$$32 \times (4.36 + 1.34) \times 10^8 \approx 1.82 \times 10^{10}$$加上 LM Head:
$$2 \times 4096 \times 128{,}256 \approx 1.05 \times 10^9$$单 token decode 约 19.3 GFLOPs。
表面看:prefill 一次算 8192 个 token,用了 150 TFLOPs;decode 每次只算 1 个 token,只用 19 GFLOPs,似乎快很多?
但这里有个关键区别:
- Prefill 是矩阵 × 矩阵($X_{[S,d]} \times W_{[d,d]}$),两个大矩阵相乘,算术强度(FLOPs / 显存读写量)很高,GPU 算力核心可以被高效利用
- Decode 退化成矩阵 × 向量($x_{[1,d]} \times W_{[d,d]}$),每次只有 1 行,而 $W$ 矩阵需要从显存完整读出,算术强度极低
结果是:decode 的瓶颈不是 GPU 算力,而是显存带宽——GPU 的算力核心大量空闲,在等待显存把权重矩阵"喂进来"。
这就是为什么 KV Cache 的显存占用、batch size、以及 W_K/W_V 的大小(即 GQA 的意义)对推理吞吐如此关键。
八、训练 FLOPs 与能耗换算
用经验公式估算训练 FLOPs
大语言模型训练常用粗略估算:
$$\text{训练 FLOPs} \approx 6 \times N \times T$$其中 $N$ 为参数量,$T$ 为训练 token 数,系数 6 来自"前向 $\approx 2NT$,反向 $\approx 4NT$"。
一次前向传播:每个参数参与一次乘加,共约 $2NT$ FLOPs(乘法 + 加法各算 1 次)。
反向传播需要计算两组梯度:
- 对输入的梯度(继续反传):约 $2NT$
- 对权重的梯度(更新参数):约 $2NT$
前向 + 反向 = $2NT + 2NT + 2NT = 6NT$。
这是数量级估算。实际会因梯度检查点重算、优化器(Adam 的状态更新)、混合精度 loss scaling 等因素略有偏差。
LLaMA-3 8B:
$$N \approx 8.03 \times 10^9, \quad T \approx 15 \times 10^{12}$$ $$6 \times 8.03 \times 10^9 \times 15 \times 10^{12} \approx \textbf{7.23 \times 10^{23} \text{ FLOPs}}$$Meta 披露的实际训练数据
Meta 在 LLaMA-3 8B 的 model card 中公开了预训练计算:
$$1.3 \times 10^6 \text{ GPU hours(H100-80GB,功耗口径 700W)}$$电能:
$$1.3 \times 10^6 \times 0.7 \text{ kW} = 910{,}000 \text{ kWh} = \textbf{0.91 GWh}$$Meta 披露的碳排放:
$$\textbf{390 tCO}_2\text{eq}$$理论 FLOPs 与 GPU 小时的连接
把理论训练 FLOPs 除以总 GPU 秒数,得到每张 GPU 的端到端有效吞吐:
$$\frac{7.23 \times 10^{23}}{1.3 \times 10^6 \times 3600} \approx 1.54 \times 10^{14} \text{ FLOP/s/GPU} = \textbf{154 TFLOP/s}$$H100 SXM5 的 BF16 Dense(无稀疏)峰值为 989 TFLOP/s(注意:494 TFLOP/s 是 TF32 Dense 的值,BF16 Dense 是其两倍),因此端到端模型浮点利用率(MFU)约:
$$\text{MFU} = \frac{154}{989} \approx \textbf{15.6\%}$$15.6% MFU 在大规模分布式训练中属于正常水平(理论峰值很难接近)。GPT-4 训练据报道约 30-38% MFU,但那是在专为训练优化的超大规模集群上。LLaMA-3 8B 的实际 MFU 偏低反映了分布式开销的普遍损耗:
| 开销来源 | 说明 |
|---|---|
| 数据并行通信 | AllReduce 同步梯度期间 GPU 算力空闲 |
| 流水线气泡 | 流水线并行边界的 bubble 时间 |
| 梯度检查点重算 | 为节省显存,部分前向激活被重新计算 |
| 优化器更新 | Adam 的一阶/二阶矩更新消耗显存带宽 |
| 训练不稳定/重启 | loss spike 回滚浪费计算 |
| 内核调度开销 | CPU 发 CUDA kernel 的延迟 |
直觉:这 15.6% 就像工厂的实际产能利用率——采购了 100% 的产能,真正有效生产的时间只有约 15.6%,其余是换模具(通信同步)、设备维护(梯度检查点)和工人换班(内核调度)的时间。
完整换算链条
训练 token 数 T × 参数量 N × 6
= 理论训练 FLOPs
÷ H100 BF16 Dense 峰值(~989 TFLOP/s)
÷ MFU(~15.6%)
= 实际 GPU 秒数
÷ 3600
= 实际 GPU 小时数
× GPU 功耗(0.7 kW)
= 总电能(kWh)
× 电网碳强度(kg CO₂/kWh)
= 碳排放LLaMA-3 8B vs GPT-3 训练能耗对比
| GPT-3 175B | LLaMA-3 8B | |
|---|---|---|
| 训练 token 数 | 3,000 亿 | 15 万亿(50× 更多) |
| 参数量 | 1,750 亿 | 80.3 亿(1/22) |
| 理论训练 FLOPs | $\approx 3.1 \times 10^{23}$ | $\approx 7.2 \times 10^{23}$(2.3× 更多) |
| 实测用电 | 1,287 MWh | 910 MWh |
| 碳排放 | 550 tCO₂eq | 390 tCO₂eq |
LLaMA-3 8B 的参数量是 GPT-3 的 1/22,但训练 token 多 50 倍,总计算量反而更大。更小的模型 + 更多的数据——这是 Chinchilla 定律(Hoffmann et al., 2022)在工程上的体现:给定算力预算,缩小模型规模、增加训练数据,能取得更好的效率。
九、总结
LLaMA-3 8B 在 GPT-3 架构基础上做了四项关键改进:Pre-RMSNorm 让深层训练更稳定(去掉均值计算和偏置,Pre-Norm 顺序让梯度有直通路径);GQA 把 KV Cache 从 MHA 的 4 GB(8K 上下文)压到 1 GB(降为 1/4),推理吞吐因此大幅提升;RoPE 把位置旋转进 Q/K 点积,天然表达相对距离并支持长上下文扩展,$\theta_\text{base}=500{,}000$ 是为 8K 上下文把旋转速度放慢 50 倍;SwiGLU 给 FFN 加了动态门控分支,用三次矩阵乘法换来更强的特征选择能力,中间维度 14336 是 Meta 实验选出的经验最优值($= 112 \times 128$,非参数对齐直接推导)。训练了 15T+ token 后总计算量约 $7.23\times10^{23}$ FLOPs,Meta 披露实际用电约 910 MWh、碳排放 390 tCO₂eq,端到端 MFU 约 15.6%(以 H100 BF16 Dense 989 TFLOP/s 为基准)。